Elasticsearch에서 아랍어 키워드 검색하기
이번 글에서는 Elasticsearch에서 아랍어 키워드 검색하는 방법과 그 삽질에 대해 알아 보고자 합니다.
영어로 된 글은 적지만 좀 있는데 한국어로 된 글은 거의 없어서 한번 정리하는 겸 해서 써봤습니다.
아랍어 기초
일단 아랍어는 중동 지역과 북아프리카 지역에서 주로 사용하고 있습니다. UN 공용어에 화자는 규모 면에서 세계 5위를 자랑할 정도로 많은 사람들이 사용합니다.
주로 우리나라에서는 제2외국어로 아랍어를 많이 선택하며, 이슬람교의 영향을 많이 받았습니다.
다들 잘 알고 있는 사실은 읽기 매우 어렵다, 반대로 읽는다 정도 그리고 모음이 없다(반모음이 있음) 정도입니다.
우리가 아랍어가 어렵다고 생각하는 이유는 바로 아래 사진으로 이해할 수 있습니다.
아랍 문자는 그 문자가 독립적으로 사용될 때와 단어에서 사용되는 위치에 따라 그 모양이 바뀝니다.
그래서 처음 배울 때 어말-어중-어두-독립형 (+함자) 까지 외워야 하는 상황이 발생합니다. (러닝커브가..)
아랍 방언
우리가 일반적으로 접하는 아랍어(문어체)는 Modern Standard Arabic(MSA, 현대 표준 아랍어)입니다. 주로 뉴스, 공공문서와 같은 공적인 자료에서 많이 사용되며 약 1300년전 사용되었던 언어입니다.
그에 비해 AD(Arabic dialects, 아랍 방언)은 지역에 따라 나뉘는데 크게 걸프(Gulf), 이집트(Egyption), 마그렙(Maghrebi, 북아프리카 서쪽지역), 그리고 레반트(Levantine, 레바논과 팔레스타인 그리고 그 근방)으로 나뉩니다. 그 이외에도 더 많이 나뉘지만 편의상 4개만 언급 하였습니다.
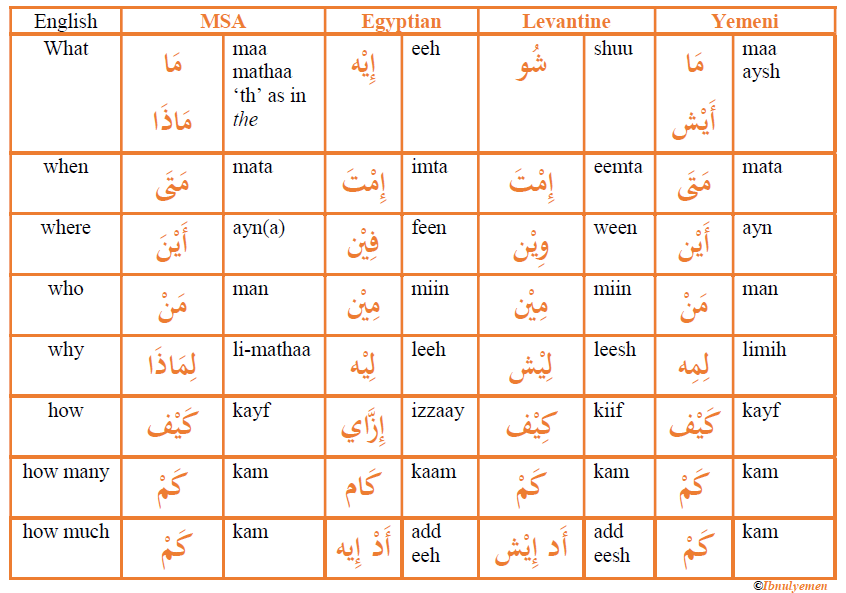
위 사진을 보면 똑같은 말이라도 지역에 따라 표기가 아예 다른 것을 볼 수 있습니다.
만약 당신이 표준 아랍어만 처리해야 한다면 이 글을 더 이상 볼 이유가 없긴 합니다. 그러나 많은 사람들이 실제로 인터넷 상에서 지역 방언을 많이 사용하기 때문에.. 서비스를 운영하는 사람 입장이라면 아랍 방언도 같이 고려해야 하는 상황이 올 수 있습니다.
아랍어 검색이 잘 안되는 이유
그래서 왜 안되느냐, 바로 아랍어 방언과 기존 영어식 ngram의 한계입니다.
(물론 더 다양한 이유가 있을 것 같습니다만, 제가 생각했을 땐 크게 두 가지 이유 같습니다)
아랍어 방언
아랍어는 아주 다양한 방언을 가지고 있습니다. 공식 석상에서는 현대 표준 아랍어를 사용합니다만, 인터넷 상에서도 다양한 방언들을 쉽게 찾을 수 있습니다.
한국어로 따져도 대한민국에서 사용하는 언어와 문화어(조선어) 가 있고, 중국 조선족이 사용하는 조선어가 따로 있습니다. 근데 더 많은 화자가 있는 아랍어는 더 다양한 방언을 가지고 있기 때문에 한계가 있습니다.
영어도 영국 영어, 미국 영어, 싱가포르 영어, 홍콩 영어 등 화자의 지역에 따라 사용하는 단어가 나뉘긴 합니다만,표기법이 크게 다르지 않고 서로 간에 대화가 통하는 정도지만 아랍어는 그렇지 않다는 사실..
그럼 ngram을 사용하면 안되나요?
문자의 위치에 따라 표기가 바뀌지 않는 영어와 한국어와는 달리 아랍어는 위치에 따라 표기가 바뀝니다.
이를 단순히 ngram으로 처리 하기에는 그 한계점이 명확합니다. -> ngram으로 자른다면 아예 다른 단어가 되기 때문에 잘 검색이 되지 않습니다.
물론 제가 검색을 해봤을 때 ngram으로 시도하는 경우도 많이 있습니다만, 이런 경우에는 indexing 해야 할 token이 너무 많아져 성능 저하 문제가 발생할 수 있습니다.
Elasticsearch는 그럼 이 사실을 모르나요?
Elasticsearch과 lucene도 이러한 부분을 잘 알고 있어서 기본 아랍어 analyzer를 제공합니다. (arabic analyzer, https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lang-analyzer.html)
물론 기본 아랍어 analyzer도 좋은 기능입니다만, 제 경험상 제대로 된 검색이 되지 않는 문제와 여러 방언이 동시에 저장된 데이터에서 검색하는데 그 한계점을 겪었습니다.
일단 기본적으로 제공하는 analyzer는 어근에 대한 Root Dictionary가 있는 analyzer입니다. 이는 영어와 한글과 같은
ISRI Stemmer
이러한 부분을 해결 하고자 많은 연구자들이 No Root Dictionary에 대한 부분을 연구 하였습니다.
그 중 ISRI(Information Science Research Institute) 에서 개발한 Arabic stemmer는 어근 사전이 없는 상태에서도 아랍어에 대한 Stemming이 가능하도록 설계 되었습니다.
기존의 아랍어 Stemmer인 Al-Fedaghi, Al-Shalabi, Khoja(?), Garside와 어근을 추출하는 단계는 유사하지만 약간의 차이점이 있습니다.
Khoja Stemmer
- 분음 부호를 제거 (원형을 찾기 위함)
- Stopword, Punctuation, numbers 모두 제거 (어근 추출에 중요하지 않은 요소이므로)
- 정관사 al ( ال ) 을 제거 (명사 앞에 붙어서 명사를 한정시키는 역할을 합니다. (Al Jazeera에서 Al이 그 정관사 Al입니다 - 번역하면 The Peninsula (아라비아 반도))
- (و, waw) 를 제거합니다.
- “و” (이하 waw) 를 제거하는 이유는 아랍어 문법을 보면 알 수 있습니다. waw는 독립적으로 사용될 때 “또는 (and)” 이란 단어로 사용되며, 자음 뒤에 장모음으로 사용됩니다.
- 이는 단어의 원형에 추가로 붙는 형태라 어근을 찾는 과정에서 불필요한 것으로 인식되어 제거합니다.
- 접미사, 접속사 제거
- 논문에서 명시된 패턴 목록과 그 결과를 비교하여 일치하는 경우 그 값을 추출합니다.
- 이 값을 이용하여 기존에 가지고 있던 어근 목록과 비교합니다.
- اوي 를 waw로 대체합니다.
- 모든 함자(글자 위에 붙은 2 반대로 뒤집은 문자) 를 alif-hamza로 대체합니다.
- 두개의 어근이 확인되는 경우를 위해 검사하고, 그 결과에 따라 문자를 어근에 추가합니다.
복잡하지만 간단하게 하면 불필요하게 꾸며주는 단어들에 대해 제거하여 최대한 어근을 찾고, 기존에 가지고 있던 어근 목록과 비교하는 과정을 거칩니다.
그러나 이런 Khoja의 방식에는 몇몇 약점이 있습니다.
- 어근 목록을 계속 관리 해야 한다는 점 (최신 데이터를 반영하지 못한다)
- 단어의 형태에 따라 어근이 원래 사용된 단어와 다르게 결과가 나온다는 점
- 이 방식에서는 다른 단어에 붙은 hamza를 alif-hamza로 모두 대체하는데, 이 hamza를 삭제하면서 원래의 뜻이 바뀔 수 있다는 점
- 마지막으로, 삭제하는 문자로 구성된 단어에 대해서는 제대로 stemming을 하지 못한다는 점
ISRI Stemmer
이런 부분을 많이 고려해서인지, ISRI Stemmer는 Khoja Stemmer와 비교하여 단어의 삭제보단 Normalizing에 초점을 뒀다는 것을 알 수 있습니다.
옆에 있는 부분은 제가 약간의 코멘트를 달아뒀습니다. - 틀린 부분 있으면 알려 주세용
- 분음 부호를 제거 (원형을 찾기 위함) > 동일
- hamza를 제거하고 그 원형을 사용하는 것 > 기존에는 hamza를 alif-hamza로 대체 하였는데 이를 원형을 사용하는 것으로 변경됨
- 접두사가 길이가 3 혹은 2 인 경우 그 접두사 제거 > 접미사, 접두사를 그냥 모두 제거하는 것보다 일정 길이 이상인 것만 제거함으로서 원형을 살릴 수 있도록 하였음.
- 만약 단어가 و 로 시작한다면, waw를 삭제 > waw를 모두 삭제하는 방향에서 장모음으로 사용되는 경우 삭제하는 것으로 그 범위를 줄였습니다.
- alif-hamza도 hamza가 아닌 alif 원형을 사용합니다. > 아마 이는 기존에 hamza -> alif-hamza로 대체 함으로서 의도하지 않은 어근 변경에 따른 문제점을 해결하기 위함인 것 같습니다.
- stem된 token이 길이가 3 이하인 경우 종료 > 길이 3 이하인 것들은 어근으로 판단하는 것 같습니다.
- token의 길이에 따라 다음과 같이 처리
- 길이 4) PR4[논문에 명시] 의 값과 일치하면 그 값을 추출하고 종료. 아닌 경우 접미사 1, 접두사 1을 S1, P1과 비교하여 포함하는 경우 삭제하고 반환.
- 길이 5) 길이 4와 비슷하지만 PR53, PR54를 사용
- 길이 6) 길이 4와 비슷하지만 PR63을 사용
- 길이 7) 여기서는 접미사 1, 접두사 1을 삭제하는데 그 목표를 두고 있음. 길이 6일 때랑 같은 방식으로 한번 더 처리한 뒤 그 값을 보고 반환
조금 더 복잡하지만, 최대한 원형을 살릴 수 있게 하는데 그 초점을 뒀습니다.
그리고 보시면 알겠지만 어근 목록을 가지고 있을 필요가 없어서 아랍어와 같이 방언이 많은 언어에게는 더 효과적으로 쓰일 수 있을 것 같습니다.
실제로 Python으로 두 Stemmer를 비교 해보니 ISRI Stemmer가 MSA, AD 모두 원형을 더 잘 살리는 것 같았습니다. (그리고 제가 봐도 잘 몰라서 그럴수 있습니다 ㅋㅋ)
Elasticsearch 플러그인 개발
Crawler가 자연어 처리를 해서 넣어 주는것도 좋은 방식이지만, 플러그인을 개발해서 쉽게 analyzing 하는 것도 좋은 방식이라고 생각했습니다.
플러그인에 대한 Reference가 잘 없어서 참고하기 쉽진 않았지만, 공식 사이트에 설명이 있으니 참고 해보면 좋을 것 같습니다.
링크: https://www.elastic.co/guide/en/elasticsearch/plugins/current/plugin-authors.html
나중에 기회가 된다면 플러그인 개발에 대해 따로 이야기 해보겠습니다.
테스트
MSA는 테스트 할 수 있는 문구를 잘 구할 수 있는데, 아랍 방언의 경우에는 구하기 쉽지 않았습니다.
결정적으로 제가 아랍 방언을 모르니.. 이게 봐도 어떤 아랍 방언인지 알 수 없었습니다.
그러던 중… ` NADI 2020: The First Nuanced Arabic Dialect Identification Shared Task ` 에서 국가/지역별로 라벨링된 트위터 데이터셋을 공개한 사실을 확인 하였습니다.
이 데이터를 이용하여 각 지역별로 Analyzer가 잘 작동하는지 기본적인 테스트를 진행할 수 있었습니다.
Egyptian
기본 문구
1 | |
Analyzer with ISRI Stemmer
1 | |
Standard Analyzer
1 | |
Yemen
기본 문구
1 | |
Analyzer with ISRI Stemmer
1 | |
Standard Analyzer
1 | |
Libya
기본 문구
1 | |
Analyzer with ISRI Stemmer
1 | |
Standard Analyzer
1 | |
테스트를 더 진행하면 좋겠지만, 분류하는데 시간이 오래 걸려서 그냥 몇몇개 댓글만 해 봤습니다.
위 예시를 보면 어떤 글에 대해서는 Standard Analyzer가 어근을 이상하게 잘려서 이상하게 tokenizing 되는 부분이 몇몇 있었지만, ISRI Stemmer에서는 그런 현상이 조금은 줄어든 것을 확인 할 수 있었습니다.
물론 더 다양하게 실험하고 그 결과를 봐야 확실하게 알 수 있을 것 같습니다. (이거 해주실분.. 있음.. 공유주세요)
그리고 ISRI Stemmer가 Sliver Bullet 이라는 의미가 아닙니다. 그냥 좀 더 나은 방법을 찾아가는 과정이지, 이는 절대 완벽한 tokenizing을 의미하진 않습니다.
elasticsearch-arabic-dialect-plugin
그냥 이런 것이 있다 정도로 소개하면 심심하실 것 같아 Elasticsearch에 적용할 수 있는 플러그인을 함께 제공 하였습니다.
Source code: https://github.com/bunseokbot/elasticsearch-arabic-dialect-plugin
Elasticsearch Plugin
혹시 Elasticsearch에 직접적으로 사용하고 싶으신 분들은 운영중인 모든 노드에 다음과 같이 설치 하시고 재시작하시면 됩니다.
./bin/elasticsearch-plugin install https://github.com/bunseokbot/elasticsearch-arabic-dialect-plugin/releases/download/v1.0.0/elasticsearch-arabic-dialect-plugin-1.0.0.zip
Elasticsearch Query
Index 생성 시 settings 내에 custom analyzer - filter에 “arabic_dialect_filter”를 추가 하시면 됩니다.
1 | |
Analyzer 테스트 하기
1 | |
문구는 Al Jazeera 개인정보보호 관련 팝업 안내문을 참고 하였습니다.
결론
음.. 어렵다.
원래 목표는 한국어로 된 자료가 없어서 한번 써 보게 되었는데 생각보다 많은 것들을 배우게 되었다.
나중에 기회가 된다면 Vectorization / Scoring 부분도 함 해보면 좋을 것 같다.
Reference
- Boujou, ElMehdi & Chataoui, Hamza & el Mekki, Abdellah & Benjelloun, Saad & Chairi, Ikram & Berrada, Ismail. (2021). An open access NLP dataset for Arabic dialects : Data collection, labeling, and model construction.
- K. Taghva, R. Elkhoury and J. Coombs, “Arabic stemming without a root dictionary,” International Conference on Information Technology: Coding and Computing (ITCC’05) - Volume II, 2005, pp. 152-157 Vol. 1, doi: 10.1109/ITCC.2005.90.
- Muaad, A.Y.; Jayappa, H.; Al-antari, M.A.; Lee, S. ArCAR: A Novel Deep Learning ComputerAided Recognition for CharacterLevel Arabic Text Representation and Recognition. Algorithms 2021, 14, 216. https://doi.org/10.3390/a14070216
- Omar F. Zaidan, Chris Callison-Burch; Arabic Dialect Identification. Computational Linguistics 2014; 40 (1): 171–202. doi: https://doi.org/10.1162/COLI_a_00169