PyClone: 파이썬 오픈소스 라이브러리 변경사항 모니터링 시스템
서론
우리는 생각보다 많은 사항을 알아보고 오픈소스 라이브러리를 사용하지 않는다.
그냥 stackoverflow가 시키니까, 다른 라이브러리에서 dependency로 걸려 있으니까 쓴다.
근데.. 이쪽을 노리고 많은 공격자들이 오픈소스 라이브러리를 타깃으로 삼기 시작했다.
https://www.codingworldnews.com/news/articleView.html?idxno=10171
관련 연구
항상 이런 일이 있을 때 마다, 관련 연구를 찾는 습관을 들이고 있다. 여튼,
PyPI나 GitHub에서는 특정 라이브러리의 dependency에서 CVE 정보가 올라오는 경우 개발자에게 알려 패치할 수 있도록 하는 기능은 이미 많이 개발되어 있다.
그러나 이러한 코드 자체에 악성 스크립트가 들어간 경우에는 개발자가 repository 들어가서 분석하는 방법 말곤아직 마땅한 방법이 없다.
서비스까진 바라지 않고 그냥 이런 정보를 정리해 둔 사이트가 있으면 좋은데 논문이나 자료들이 많이 없어서 어떻게 해야 할지 잘 몰랐다.
PyClone
그래서 그냥 만들기로 했다.
우선 Python 라이브러리만 대상으로 하고, 나중에 더 커질 수 있으면 다른 라이브러리도 할 수 있으니 확장성을 고려했다.
생각보다 만들기로 마음을 먹은 뒤에는 일이 쉽게 풀렸다. 역시 인간은 만들기로 마음을 먹는 것이 제일 중요하다.
탐지해야 할 것
원래는 소스코드 실행을 통해 변경 사항이 있는 경우 그 사항을 모니터링 할려고 했는데, 생각보다 리소스가 너무 많이 들 것 같아 두 가지 요소만을 고려하여 우선 저장 하도록 했다.
단, 나중에 이 항목은 추가될 수 있다는 가정 하에 작성했다.
도메인 / IP 주소
소스코드 정적 스캔을 통해 도메인, IP 주소가 있는 경우 그 정보를 저장한다.
실행 파일
실행 파일이 있는 경우 파일명과 SHA256 해시 정보를 저장한다.
작명
원래부터 작명은 즉흥으로 했었어서 그냥 Aviation Hazards 보다가 Cyclone이 보여서 Python + Cyclone = PyClone 으로 지었다.
개발
PyPI의 경우 다행(?) 스럽게도 RSS를 통한 패키지 업데이트 정보를 제공한다.
그래서 일정 시간마다 패키지 정보를 스캔하고, 그 정보를 저장한 뒤 Detection Pipeline(탐지해야 할 것) 을 거치도록 했다.
그리고 라이브러리 정보 중 메타데이터를 이용한 상관관계 분석이 가능하도록 필요한 것으로 판단되는 정보 중 최대한 많은 정보를 데이터베이스에 저장했다.
처음에는 그냥 데이터베이스에 저장하고 그 데이터를 구경했는데, 생각보다 많은 데이터가 저장되서 시각화가 필요하였다. 그래서 요즘 공부하고 있는 Next.js (+ Typescript) 를 이용하였다.
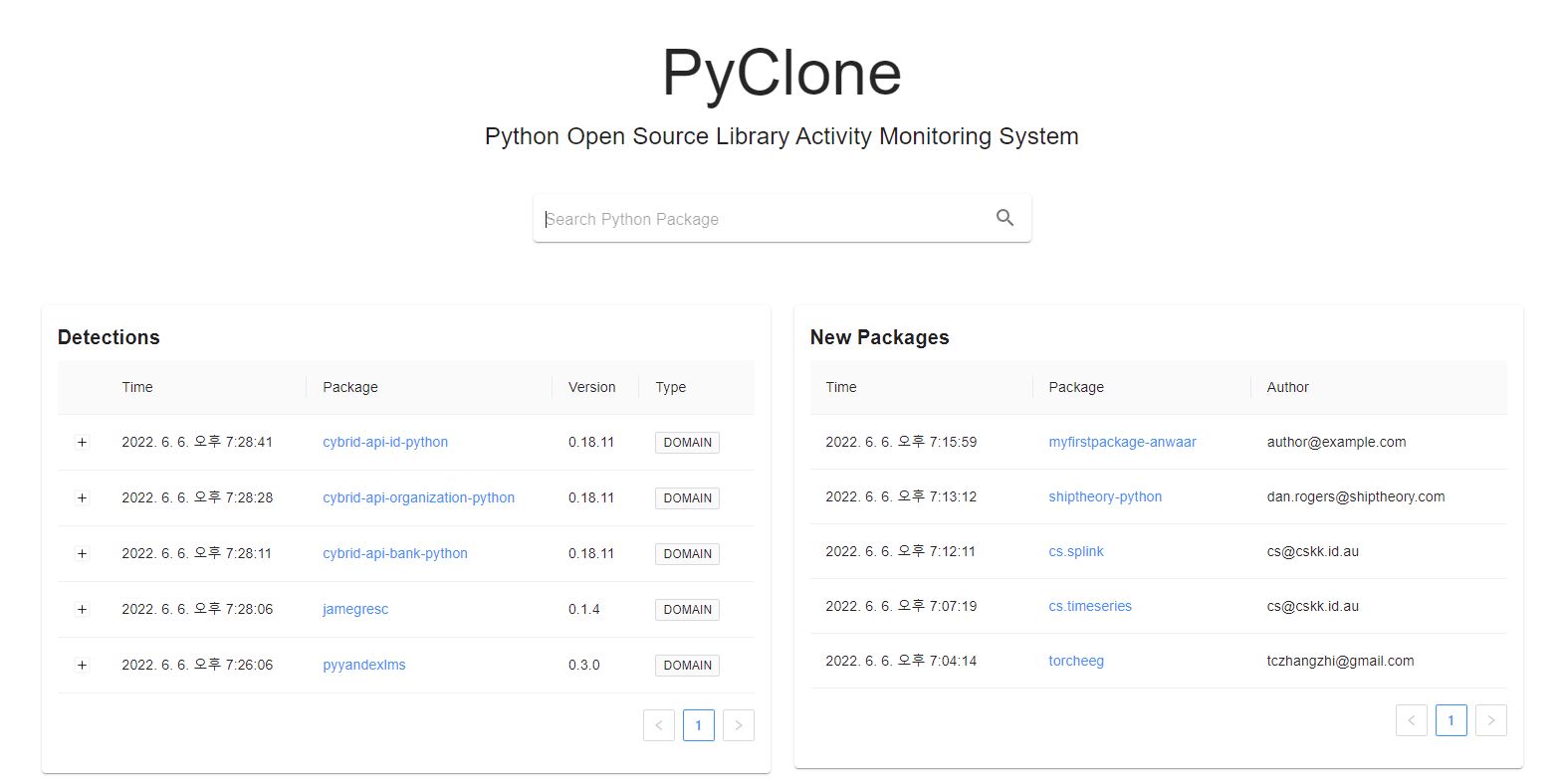
바로 접속하면 다음과 같은 화면이 뜨고, 내가 원하는 패키지를 검색할 수 있도록 하였다.
내가 쓰는 곳
내가 이걸 활용해서 요즘 쓰는 곳은
- stackoverflow나 다른 dependency / github issue에서 추천하는 라이브러리 안전성 검색
- 탐지 동향 구경하기
- 새로운 패키지 검색하기
정도다.
사실 내가 쓸려고 만든 수준이라서 많은 디자인적 요소가 없다. 직관적이기만 하면 되서 그냥 그렇게 했다.
혹시.. 디자인 하기 귀찮아서 그런거 아니냐고 하면 사실 맞다.
개발 스택
PyClone을 개발하는데 사용한 개발 스택은 다음과 같다.
- Backend
- FastAPI
- Nginx
- MySQL
- Frontend
- Typescript + Next.js
- Material UI
- Ant Design
- Infrastructure
- 2 CPU Core / 4 GB RAM
여담이지만, 로컬 개발 환경에서는 검색 엔진으로 Elasticsearch로 운영하려 했으나 서버 사양 문제로 OOM(Out of Memory) 문제가 계속 발생하여 그냥 MySQL에서 쿼리 + 인덱싱 최적화 하는 방향으로 잡았다.
그리고 서버 리소스 자체가 한계가 있는지라 최대한 최적화 하는 방향으록 가야 했다.
나중에 시간되면 이 과정에서 있었던 일을 공유하면 좋겠다. (라고 하지만 언제할 수 있을진 잘 모름)
API
PyClone에서는 외부 연동 용이성을 위해 HTTP API와 Documentation을 제공한다.
FastAPI는 swagger-ui랑 바로 연동되서 docs 만드는데 별로 많은 작업이 필요하지 않아서 좋다.
데이터가 필요하다면 그냥 API를 통해서 가져가면 된다. 단, 너무 자주 요청하게 되면 서버가 뻗을 수도 있으니..
제발 적당히 해주세요.. ㅠㅠ
Conclusion
생각보다 재밌는 데이터가 많아서 아마 당분간은 여기서 나온 데이터만 볼 것 같다.
오랜만에 다시 해 보는 오픈 서비스였는데 역시 서비스를 만드는 것이 제일 재밌다.
Future Work
처음 시작은 오픈소스 라이브러리 모니터링 도구를 만드는데 그 목적을 가지고 있었지만, PyPI 말고도 더 많은 Repository를 대상으로 하기 위해 확장하고 있다.
그리고, 데이터를 모니터링 하던 중 생각보다 키보드 실수를 노린 공격이 많은 것을 확인해서 관련 기능을 추가하고자 하고 있다.
생각해 둔 기능은 대충 있는데, 아직 다 테스트를 안해봐서 조금 더 데이터가 쌓이면 업데이트 하도록 하겠다.
아마.. 퇴근하고 하는 것이라 언제 완성될 진 모르겠지만 그래도 생각한 대로 되면 꽤 재밌는 데이터가 나올 것 같다.
언젠가 쓸 수 있겠지..
변경사항
1.0.1 (2022.06.07)
1. 소스코드 정적 스캔 방식 변경
1.0.0 버전에서는 정규표현식을 이용한 도메인, IP 주소를 추출 하였다.
이는 매우 빠르게(?) 할 수 있다는 장점이 있지만, 실제 그 문자열이 사용되는지 확인할 수 없다는 문제를 가지고 있다. 그리고 주석에 링크가 있는 경우에도 탐지되서 불필요하게 많은 탐지 로그를 남긴다는 문제를 가지고 있었다.
1.0.1 버전에서는 파이썬 스크립트를 AST (Abstract Syntax Tree, 추상 구문 트리)로 표현, 분석하여 문자열을 추출하여 비교하는 방식으로 변경 하였다.
이를 통해 기존 데이터 중 일부를 샘플링하여 테스트 한 결과 코드 내 주석 등에서 사용된 링크에서 정보를 파싱하지 않고 실제 코드 내에서 사용되는 URL에 대해서만 파싱하는 것을 확인 하였다.
2. E-mail Reverse Search 기능
이메일 리버스 검색 (소유자의 이메일 - 패키지, 소유자의 이메일 도메인 주소 - 패키지) 지원 기능을 추가함.
특정 유저가 무작위로 리포지토리를 생성하는 행위 혹은 소유자의 이메일이 등록된 도메인이 만료된 경우를 탐지하기 위해 해당 기능을 추가 하였다.